argo-workflows
ArgoCD läuft zentral in einem Cluster, statt sie in jedem Kunden-Cluster in einem argocd namespace bereitzustellen. -> Kunden-Cluster -> argocd namespace. Es gibt pro Kunde einen dedizierten Namespace, der ausschließlich für die Workflows dieses Kunden verwendet wird (nicht für die App-Bereitstellungen, dafür ist nicht Gitlab sondern ArgoCD verantwortlich).
Projektziele
- Long-Running Prozesse als DAG-s auszufuehren
- Einzelne Knoten manuell neustarten, anhalten zu können um die Abhängigkeiten von untergeordnete Knoten zu erfüllen
- Manuelle Steuerung der "K8s Jobs" mit replayability
GitLab
.git-cli.yaml
Central Cluster

Namespace 1
Workflow
Customer 1
Kubernetes Cluster
Apps
Customer 2
Kubernetes Cluster
Apps
Meine Lösung
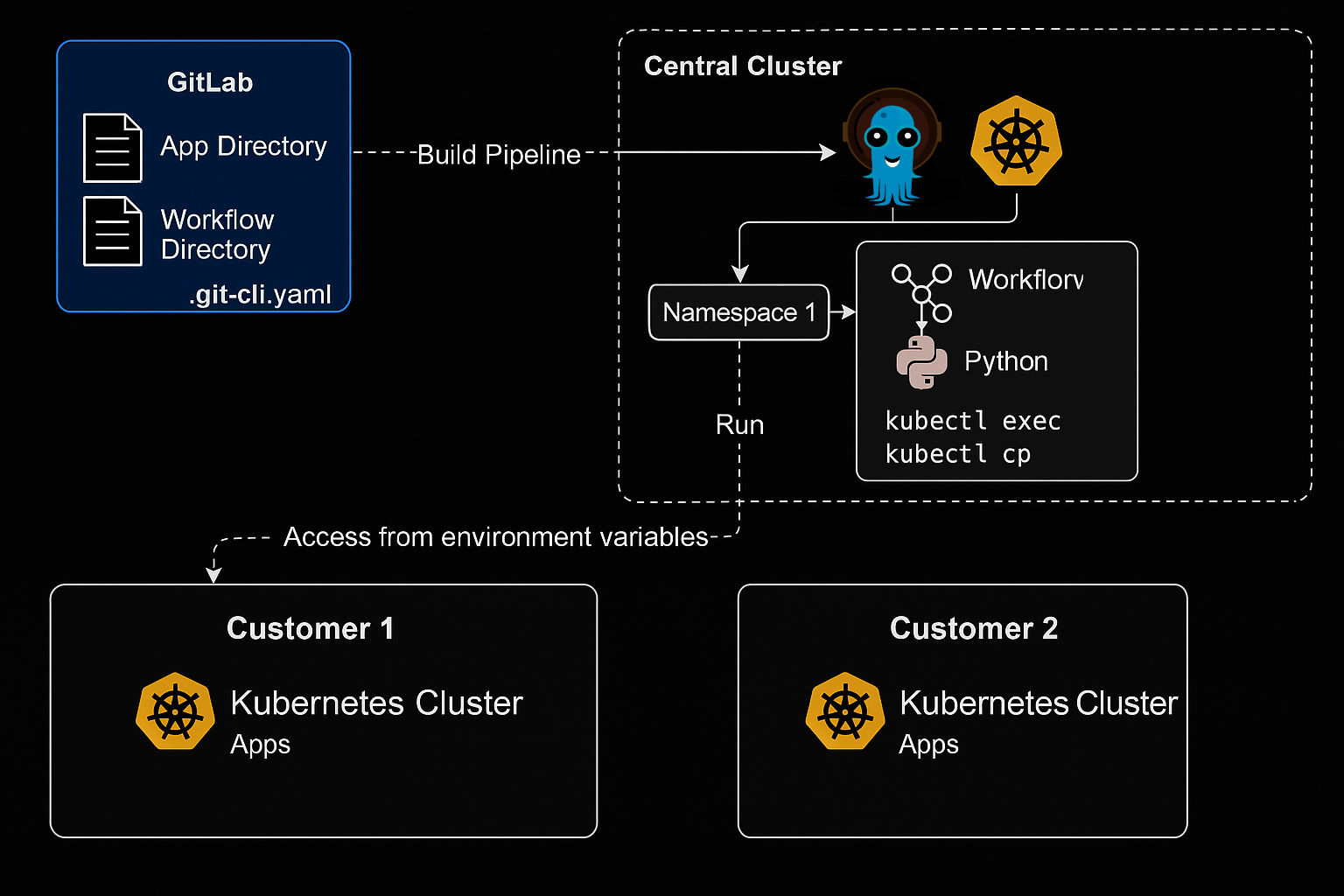
Stell dir einen kubectl apply Befehl vor der von Gitlab aus ausgeführt wird. In GitLab gibt es pro Kunde ein Verzeichnis für Apps (um das Produkt zu deployen) und eines für Workflows (um in den zentralen Cluster die Workflows mit Umgebungsvariablen aus Apps zu deployen ).
Diese Umgebungsvariablen enthalten Credentials (z.B. Tokens, kubeconfigs), die von Argo Workflows bzw. den darin laufenden Containern verwendet werden. Innerhalb des Containers/der Container wird dann z.B. ein Python-Skript ausgeführt, das kubectl exec, kubectl cp usw. nutzt.
Die Container in den Workflows, die im kundenspezifischen Namespace im zentralen Cluster laufen, verbinden sich authentifiziert zu den jeweiligen Kunden-K8s-Umgebungen.Die Authentifizierung läuft also nicht durch ArgoCD selbst, sondern durch dynamische, im Workflow gesetzte Zugangsdaten.
Durch diese Weise kann man sagen, dass die Kundenzugriffe keine Ueberschneidung haben und klar getrennt voneinander sind. Jeder Namespace hat nur Zugriff auf den jeweils dafür vorgesehenen Kundenbereich – kein Zugriff zwischen den Namespaces/Kunden.
Ergebnisse
Nach der POC Phase wir die Lösung eine zerbrechliche bash Implementierung ablösen die viel manuelle Eingriffe benötigte unter anderen On-Call-Rotations und Incident Management. Die Lösung wird für Berechnungen verwendet die übernacht laufen, Long-Running Apache Spark Jobs die als K8s Jobs laufen. Die Spark Jobs dienen für die Risikoanalyse von Finanz Instituten.